Intelligent Document Extraction
Every submission profile, complete and accurate without the manual grind.
Insurance Broker & Underwriting Firm
Case Study · 2025
About this product
An AI-powered document extraction platform built for insurance brokers and underwriters automating data collection from loss runs, schedules of values, and complex submissions, identifying missing fields, validating data completeness, and generating accurate, comprehensive submission profiles with 80% greater accuracy.
Timeline
14 weeks
Category
AI / ML
Delivered
2025
Stack
Product Preview
Why it works
Measurable impact, by design
80%
Extraction Accuracy Improvement
vs. manual data collection baseline
92%
Less Manual Effort on SOVs
property and risk data auto-extracted
5×
Faster Data Analysis
AI replaced manual document review
85%
Faster Document Review Cycles
key fields surfaced in seconds
Overview
The situation
Insurance brokers and underwriters process hundreds of submissions every week each one a collection of loss runs, schedules of values, policy documents, and supporting data files that arrive in inconsistent formats and varying levels of completeness. The manual process of collecting this data, validating it, identifying what was missing, and assembling a complete submission profile was consuming enormous amounts of underwriter time and introducing errors that affected risk pricing accuracy. We built an intelligent document extraction platform that automated the entire intake-to-profile pipeline handling multi-source data collection, preprocessing, gap identification, validation, and comprehensive profile generation giving the team more accurate submissions in a fraction of the time.
Challenge
What we had to solve
Insurance document data is notoriously heterogeneous loss runs from one insurer look nothing like loss runs from another, schedules of values can span dozens of columns in inconsistent formats, and critical fields are frequently missing or buried in narrative text. A rules-based extraction system breaks the moment a new document format arrives. The AI had to understand document content contextually rather than positionally extracting the right data from the right place regardless of how the document was structured, and knowing when a required field was absent rather than just unlocated. Beyond extraction, the validation layer had to distinguish between genuinely missing data and data present in an unexpected form.
What it does
Core capabilities
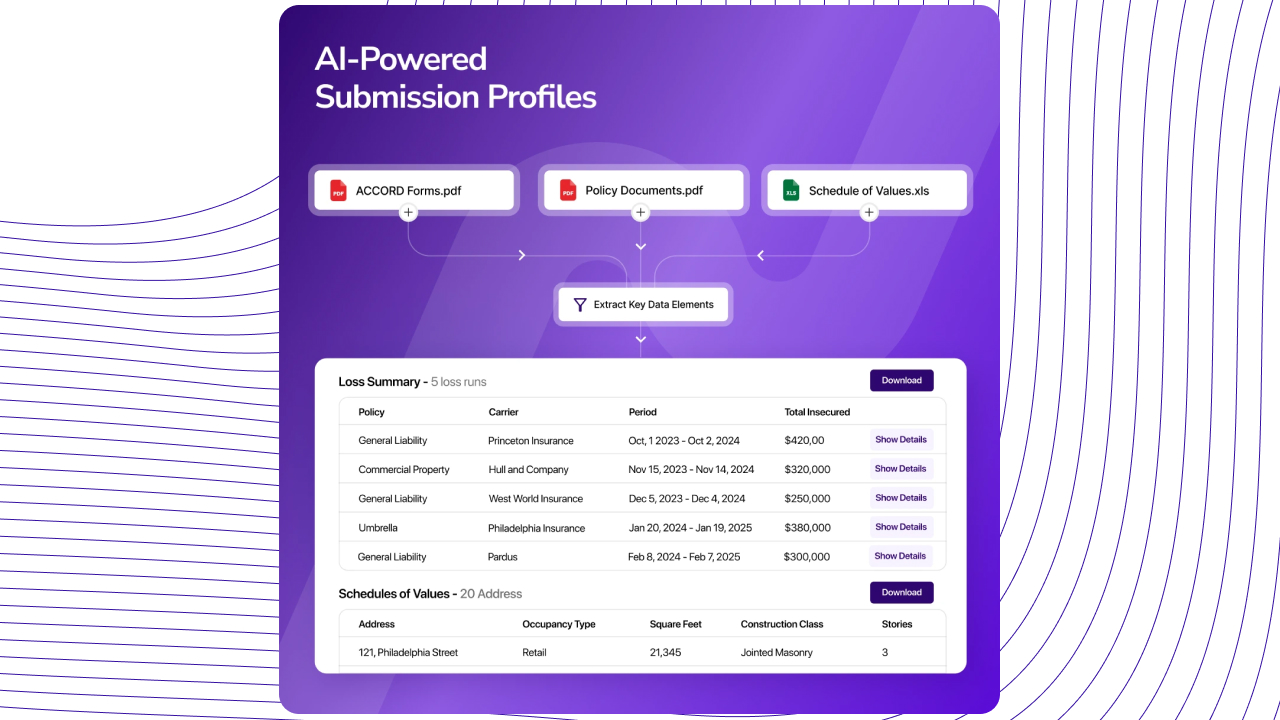
Multi-Source Data Collection & Preprocessing
The platform ingests insurance documents from any source uploaded files, email attachments, and integrated document management systems processing loss runs, schedules of values, acord forms, risk questionnaires, and financial statements through a cleaning and normalisation pipeline before extraction begins. Tabular documents with multi-column layouts, merged cells, and inconsistent header formats are handled by a dedicated table extraction layer that doesn't depend on positional assumptions. The result is a consistent, structured internal representation of every document regardless of how it arrived or how it was originally formatted.
Contextual AI Extraction & Field Mapping
The extraction engine identifies required fields from unstructured text, tables, and mixed-format documents using a fine-tuned NLP model that understands document content contextually rather than positionally. Loss run data buried in narrative paragraphs, property values embedded in non-standard table formats, and coverage descriptions spread across multiple pages are all handled without requiring document-type-specific templates. Every extracted value is tagged with its source location and a confidence score, giving underwriters full visibility into the AI's certainty and a direct path to the source passage for verification.
Gap Identification & Intelligent Validation
The gap identification engine cross-references extracted data against each document type's required field schema flagging missing fields and incomplete values with specific, actionable descriptions rather than generic error messages. The validation layer applies business logic rules across the submission package: cross-checking policy limits against coverage descriptions, validating loss run date ranges, and confirming schedule of values totals are mathematically consistent. Where required data is missing but can be supplemented from other documents in the same submission package, the system proposes a supplemented value with its source attribution for underwriter review and approval.
Comprehensive Submission Profile Generation
Validated extracted data is assembled into complete, structured submission profiles covering all required underwriting fields with data insights about risk patterns, historical loss trends, and pricing signals surfaced from the submission data. Profiles are generated in formats compatible with the team's underwriting platform and presented through a review interface where underwriters can inspect extracted values, review gap flags, and approve AI-generated supplementations before final submission. The system handles high submission volumes without increasing team headcount, enabling underwriters to focus on pricing decisions rather than data assembly.
Outcomes
Submissions assembled faster, gaps caught earlier, underwriting decisions made with better data.
80%
Improvement in extraction accuracy
vs. manual data collection and entry
92%
Reduction in manual effort for SOVs
property and risk data extracted automatically
5×
Faster complex fund data analysis
AI extraction eliminated manual review bottlenecks
85%
Faster document review cycles
key fields and clauses surfaced instantly
100%
Submission completeness validation
every profile gap flagged before underwriter review
14wks
Delivered on schedule
discovery to production-ready extraction platform
Our underwriters were spending most of their day chasing missing data and manually assembling submissions from inconsistent documents. The extraction platform changed that entirely profiles arrive complete, gaps are already flagged, and our team can focus on pricing decisions instead of data entry. The accuracy improvement alone has made a measurable difference to our risk pricing.
Insurance Broker & Underwriting Firm
Client, Insurance Operations
Want results like these?
Let's talk about what we can build together.